Category: Software
-

Schmedium Data: Building little data pipelines with bash
Over at plotdevice.bengarvey.com I have a bunch of one-off dataviz projects, experiments, and analyses. They all run on data, but sometimes it’s not easy to get, so I end up trimming and transforming data into something I can work with. We’re not talking about big data here, more like small or medium data. Schmedium data.…
-
10 Things I’m Doing After Reading The Principles of Product Development Flow
A few weeks ago I showed this slide during a talk I gave to clients of RJMetrics. The Goal is legendary in my family as a guide for unlocking throughput in manufacturing. Garvey Corp’s entire business model is helping companies exploit constraints and increase profits. It got me off to a great start in manufacturing,…
-
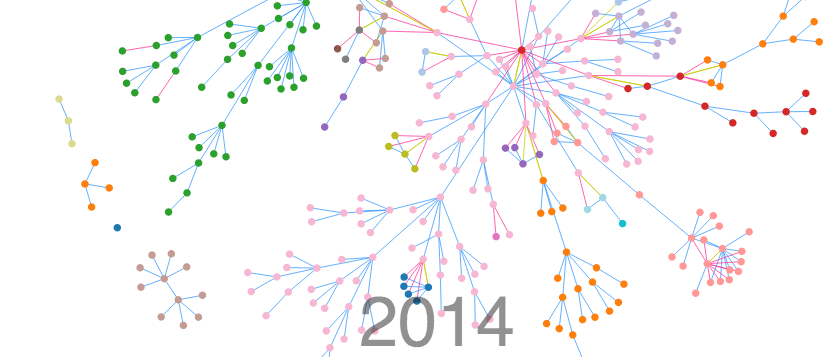
Announcing Lineage: A Family Tree Data Expression Engine
Last week at the Philly JS Dev meetup, I demoed a new project I’ve been working on called Lineage. It all started as a way to try and visualize all the research my Aunt Peggy has done over the last 50 years. Using D3, I was able to build a way to search, filter and…
-
Best Things This Year (2013)
Anecdotally, it seems like a lot of people shook up their lives in 2013. I certainly did. Here are the best things that happened to me in 2013. 1. RJMetrics – In March I started working at RJMetrics, an e-commerce data analytics firm in center city Philadelphia. Leaving Garvey Corp was a difficult decision, but…
-
D3.js Talk at Philly JS Meetup
I’m going to give a talk titled Data Expression with D3 and Null Family Values at the Philly Javascript Dev meetup on January, 22. I’ll also be giving a demonstration of an awesome D3 project I’ve been working on. Here’s a sneak peak:
-

Best Things this Year (2011)
Here are some best things I’ve come across this year. Not all are new, or even new to me, but they kicked ass in 2011 1. Kids Dungeon Adventure – A floortop RPG for pre-school age kids and their geeky parent(s). What started out as a little game with my daughter grew into a full…
-
Launched: Evidensity for Highrise
For the last few weeks I’ve been working on a new analytical dashboard tool for Highrise and it finally launches today! Read about it here. In the launch post I talk about what makes Evidensity different from other tools and my worldview on sales dashboards: Some people don’t want customizable line graphs They want actionable…
-
Pwning Complete
I can put the AK back on the shelf now. Previously: 37 Signals Sent Me a Gift for Pwning their Leaderboard
-
New Adventures in HTML5
In the last year I started hearing a lot of hype about html5. So far I’ve been impressed. They’ve clearly expanded it to become more of a platform for rich graphics. Here are some cool projects I’ve worked (or am working) on. Sparklines in HTML5 HTML5 Ball Bouncing HTML5 Gravity Ball Rock the Animals (Beta)
-
Rob Kolstad is an Asshole
This month’s Wired has a great article (not online yet, so no link) by Jason Fagone about the International Olympiad in Informatics where high school students from all over the world compete to solve problems through software. It’s fiercely competitive and has its own sub culture of super stars, namely Gennady Korotkevich of Belarus, who…
-
Twitter Tip: Use Favorites as Bookmarks
The most neglected feature of Twitter has to be favorites. It’s not used for much and none of the clients do anything interesting with them. Unlike Facebook’s “like,” categorizing a tweet as a “favorite” seems like a big commitment and the new Retweet features seem to support the concept better anyway. So what do you…
-
Could Twitter Have Worked in 1999?
For many years the Internet has brought us ideas and services that we wish we had thought of first. ?Most technologists wish they could go back in time and hit big with online auctions, classifieds, blogging software, and social networking. ?Microblogging (ie. Twitter) is the latest and greatest of these facepalming ideas because it’s so…
-
OMI Issues
Attention OMI players. I’m aware of an issue in the game Odd Just Don’t Believe It. Looks like someone is able to shoot twice and I’m trying to figure out why. Update: I brought Mr Chocolate back to life. I think I know what the problem was.
-
Twitter
I added the Twitter Tools plugin for wordpress and I set it to create a blog post every time I posted an update. (Don’t know what Twitter is? Go here).? Follow me on Twitter. It looks a little strange on this page now with a ton of one line posts, but I’ll figure it out…
-
Odd Man In Bug List
I’m gearing up for a big update on Odd Man In.? If you know of any bugs, leave them in the comments here and I’ll make sure they get added.
-
How to Handle a Service Failure
I recently mentioned my extensive use of tadalist, created by 37 Signals, as part of GTD. Tadalist is a free project, but they have a number of web based paid project management programs such as BaseCamp. They had a two hour downtime today and posted the following messages to keep customers updated. Despite having…
-
Getting Things Done
I heard about David Allen’s Getting Things Done a long time ago and I procrastinated in getting it.? It sounded like a system I could use, since my day usually consists of handling (and keeping track of!) a thousand tiny tasks.? I got the book for Christmas and according to my wife it’s the best…
-
Odd Man In issues
I fixed an Odd Man In game that was busted for a few weeks. My apologies to everyone in that game. I think the game update script was interrupted causing the round to be halfway over and freezing the game.
-
Odd Man In messages
Odd Man In has been around for almost three years now and in that time 226,337 messages have been sent back and forth between players. That’s hard to believe.
-
Looking for a good (free) FTP client for OSX
So far I’ve been using the free version of Cyberduck, and it’s painfully slow. Anyone know of a good, free FTP client for Mac OSX?